JpegOrientationとRotateFlip
携帯で撮った写真を,tbasicで表示するとします。それには,その画像ファイルの大きさのグラフ画面をGScreenを開いて,LoadPictureコマンドで,そのファイルを表示させるだけです。これはtbasicでの基本的なグラフ処理です。
これはこれで良いのですが,この方法では,画像によっては,

と横向きに表示されることがあります。ところが同じファイルを画像表示アプリ,例えば,フォトで開くと,

となります。こちらが期待するものでしょう。では,tbasicでもこのように表示するにはどうしたら良いのでしょうか。
それは,画像を回転させれば良いでしょう。
今までtbasicでは,画像回転はできませんでしたが,Ver.1.62で画像回転コマンド,RotateFlipをサポートしました。ここでは,この周辺の事柄について説明します。
RotateFlip
今まで,tbasic内での画像回転はできませんでしたが,Windowsでのexplorerを使えば簡単にできるので,必要な場合,それで対応可能でした。しかし,検討の結果,RotateFlipは実現可能なので,今回サポートしました。
tbasicのRotateFlipはC#でサポートされているものと機能的にほぼ同じで,高速に動作します。指定方法は少し異なります。
RotateFlip(Angle)
RotateFlip(Reflection)
の形で指定します。RotateFlip(Angle)は,現在のグラフ画面をAngleだけ時計回りに回転させます。Angleの取れる値は,90度,180度,270度のみです。次のように文字列の形式で記述します。
RotateFlip(“90”),RotateFlip(“180”),RotateFlip(“270”)
RotateFlip(Reflection)現在のグラフ画面をReflectionで指定された方法で反転させます。反転はx軸,y軸に関する反転のみです。
RotateFlip(“x”)は画像をx軸に関して反転させます。
RotateFlip(“y”)は画像をy軸に関して反転させます。
このRotateFlipを使って,上の(1)の画像に対して,
RotateFlip(“90”)の処理をすれば(2)の画像になります。
Exif,Orientation
tbasicで画像が横向きになっていた場合,上のように,RotateFlipで対応可能ですが,フォトを使った場合,元々横向きになりませんでした。この違いは何でしょうか。
フォトの場合,実は,上の処理を自動で行って回転処理後の画像を表示していたのです。そして,この自動処理を可能にするのが,Exifです。
Exifは”Exchangeable image file format for digital still cameras”のことで,デジタルカメラで撮影した際の,カメラの状態の情報を画像ファイルに埋め込むための仕様です。デジタルカメラで作成されたJpegファイルに格納されます。
カメラのメーカー,撮影日時,シャッター速度,絞り,等々多くの情報を記録することができます。
この中で,画像方向 Orientation があります。デジタルカメラで撮影・保存された画像は,カメラの位置により方向修正が必要な場合があります。このとき,その修正方法を記述するものです。
Orientationは1~8の整数値を表し,次の意味を持ちます。
1 : 回転なし
2 : 左右反転
3 : 時計回りに180度回転
4 : 時計回りに180度回転かつ左右反転
5 : 時計回りに90度回転かつ左右反転
6 : 時計回りに90度回転
7 : 時計回りに270度回転かつ左右反転
8 : 時計回りに270度回転
JpegファイルのOrientation値が1でない場合は,その値に応じて画像を回転等させれば,正しい位置に画像が表示されます。
実際,(1)で表示された画像は,Jpegファイルで,そのExifのOrientation値は6でした。
フォトが(2)の画像を表示可能なのは,画像ファイルのOrientation値を利用して,その値に応じた変換を施した後に,画像を表示しているからです。
tbasicでOrientaionの取得
Orientation値を知ることができれば,目で画像を見なくても位置修正が可能ですが,では,Orientation値はどのようにすれば知ることができるのでしょうか。いくつかの言語で実装する例があります。例えばC#では,bitmap.PropertyItemsを利用して,Orientation値を取得できます。直接値を示す関数がある言語もあります。現在,tbasicではそのような関数はありませんが,tbasicでもReadAllBytesを利用すれば,Orientation値を与えるユーザー定義関数を作ることができます。以下にそのプログラムを挙げますが,ここでは,その仕組みを簡単に説明します。
Exifの詳しい内容はその仕様書,例えば,CIPA DC-008-2026で知ることができます。
(1)Exifデータは,Jpegファイルに埋め込まれているので,Jpegファイルの内容(バイナリデータ)を読み取る必要があります。ReadAllBytesを利用すれば,バイナリデータを取得できるので,それを利用します。
・Exifデータはファイルの先頭に近い部分にあり,バイトデータパターンとして定められているので,先頭から1000バイト程度読み込み,それを16進byteデータの文字列として保存します。それを例えばByteDataStrとします。バイトパターンをこのByteDataStr内で検索して,値を求めます。
(2)Exifデータの確認。
・Exifデータは,SOIの直後APP1で始まります。これは16進byteで表すと,FFD8 FFE1となり,これがあれば,Exifデータがあることになります。
(3)エンディアンの確認。Exifデータはエンディアンに依存します。ExifデータのエンディアンはTIFF Headerに書かれていますが,それは,Exif識別コード(457869660000)の次の2Byteにあります。これが
・4D4Dならば,ビッグエンディアン,4949ならばリトルエンディアンです。
(4)Orientation値を求める。
・ビッグエンディアンの場合は,0112 0003 00000001 000?0000 のパターンで,?の部分に値(1~8)が入る。
・ リトルエンディアンの場合は,1201 0300 01000000 0?000000 のパターンで?の部分に値(1~8)が入る。
自動回転のデモプログラム
上の考えで,Orientation値を求めることができますので,これを使って,回転補正のデモプログラムを作ってみました。以下に紹介します。
Orientation.tbtという名前にしました。このプログラムは,ver. 1.62 で動作します。起動すると,
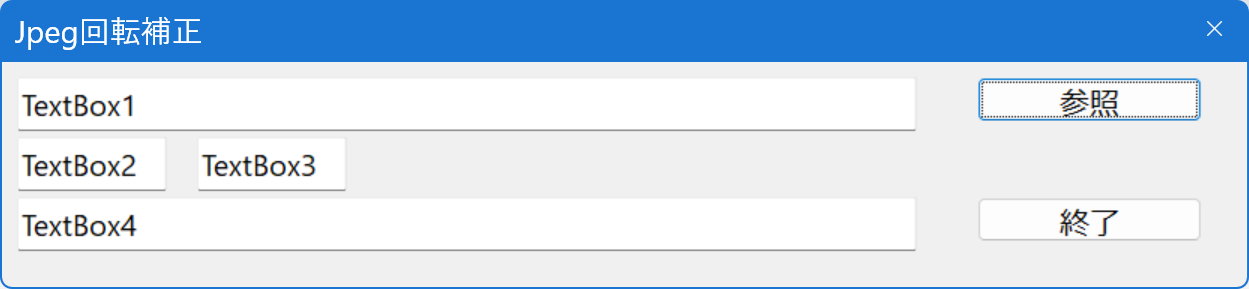
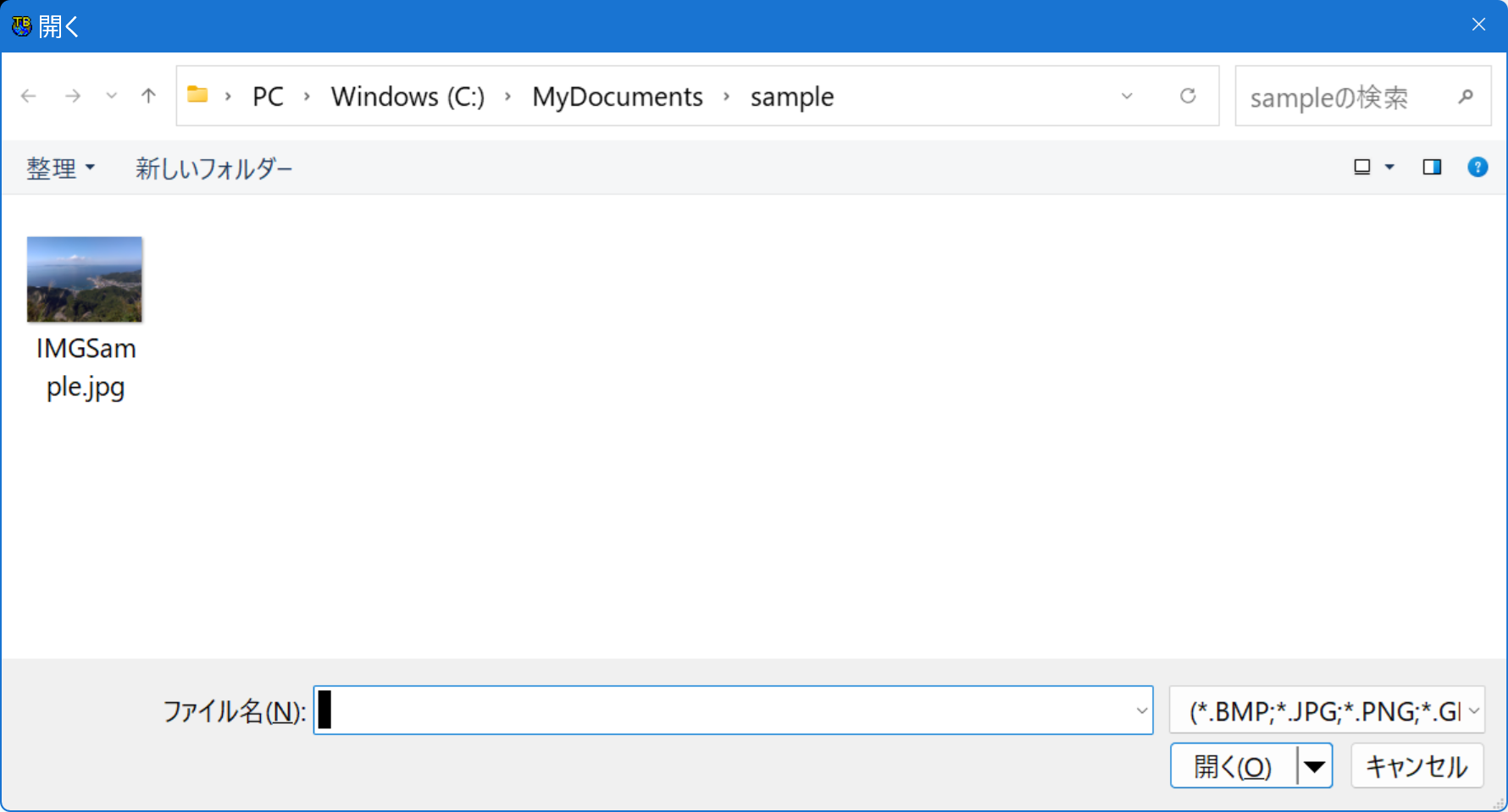
となります。参照ボタンを押すと,Open画面になり,例えば次のようになります。
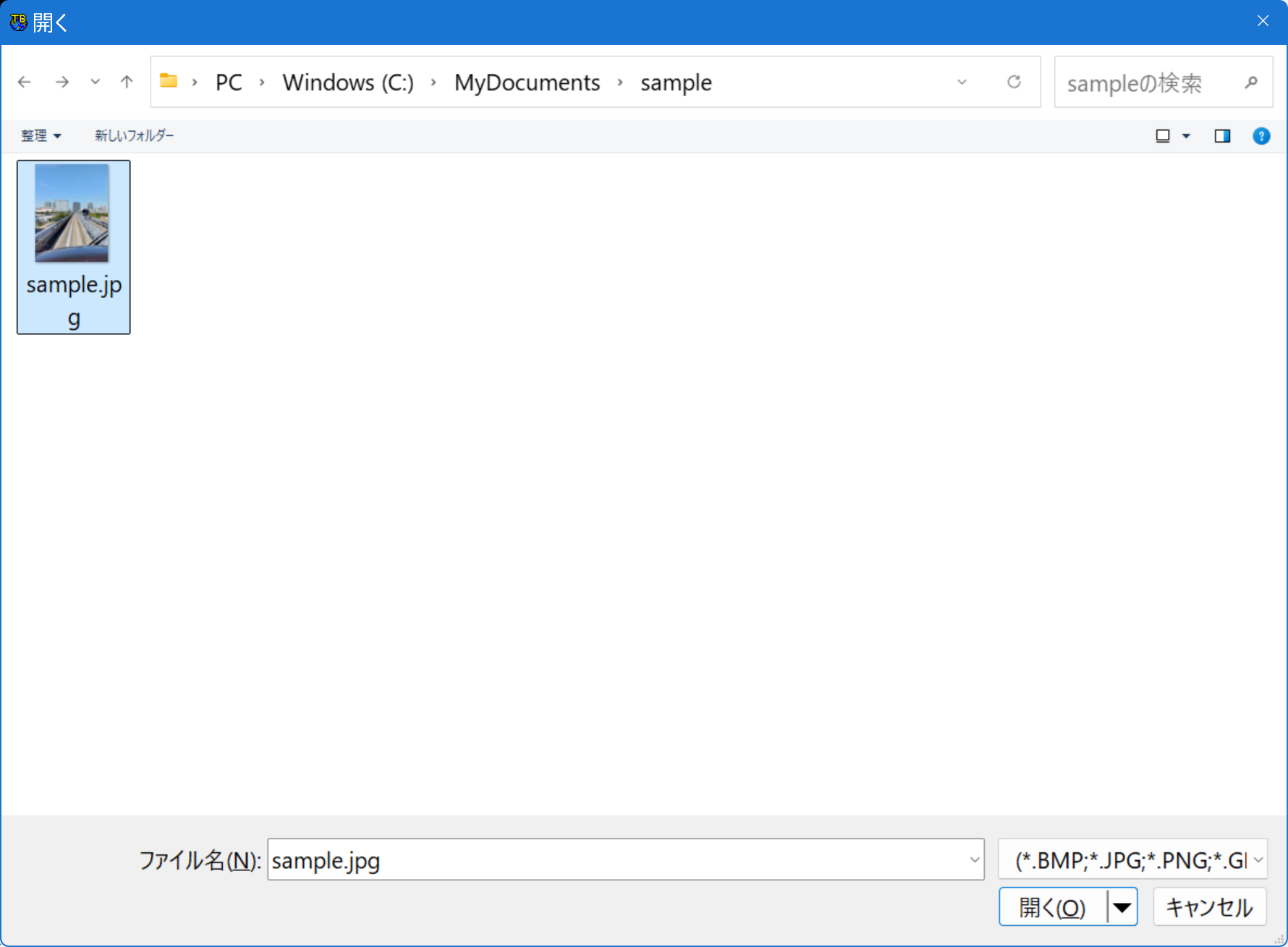
ここで,開くボタンを押すと,Sample.jpgがLoadされて,
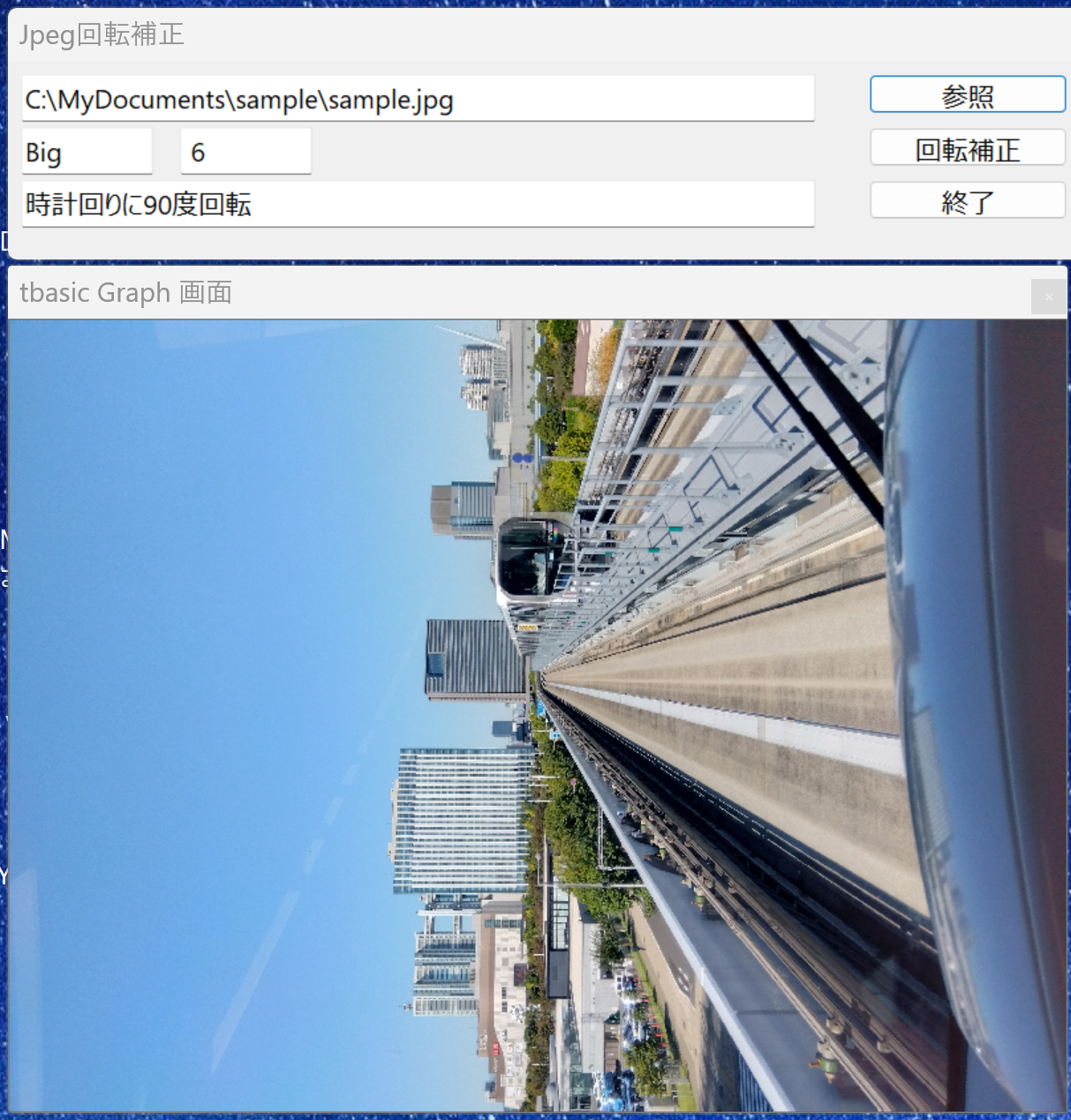
と表示されます。画面が横向きになっています。Orientaion情報が上に表示されています。このファイルは,ビッグエンディアンでOrientaion値6です。この意味が下に表示されています。時計回りに90度回転させれば良いの意味です。回転補正ボタンを押すと,
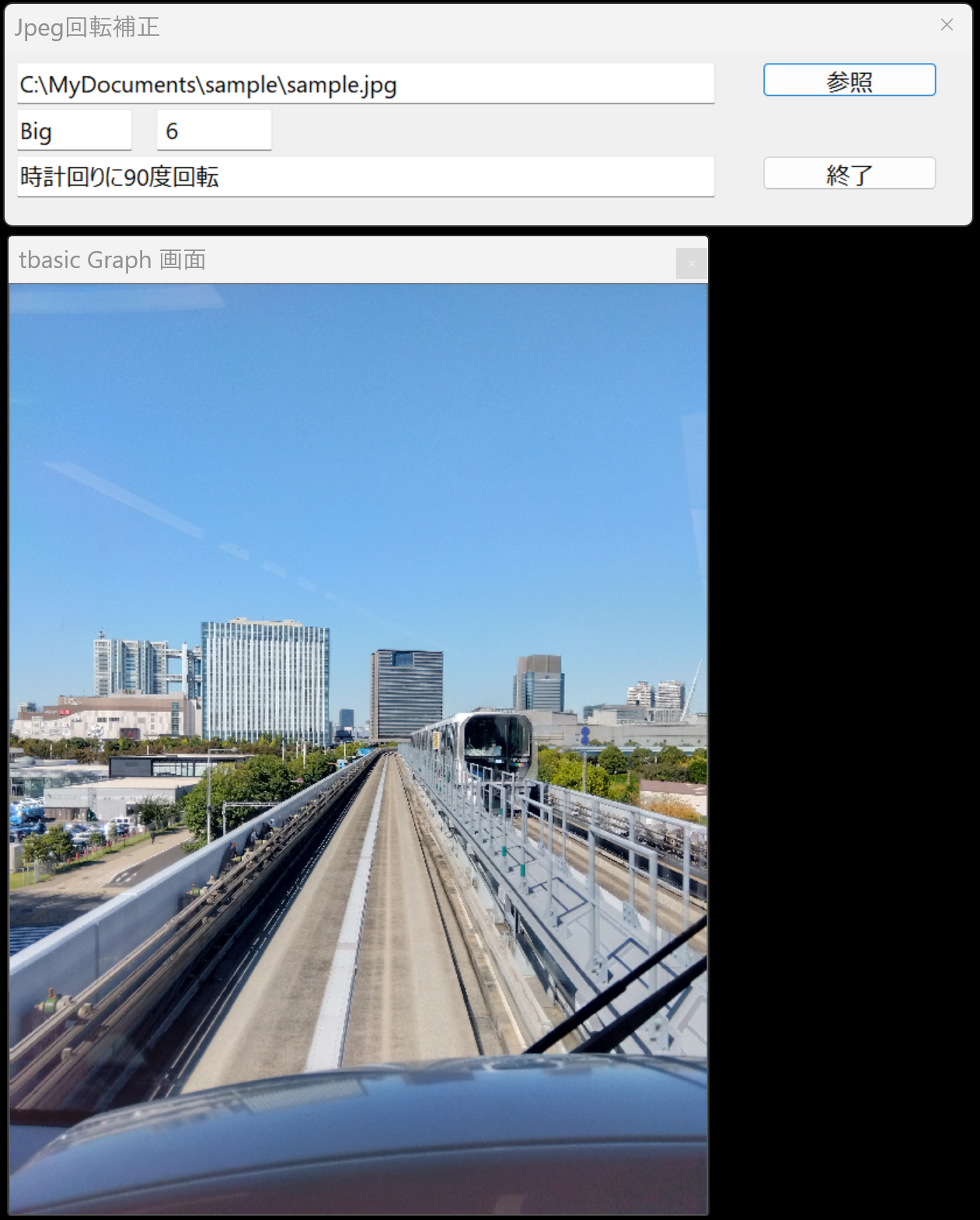
となります。このプログラムはここにあります。約150行ほどのプログラムで,
Orientation値を求める部分は30行程度です。RotateFlipの使い方の例にもなっています。